
https://papers.nips.cc/paper/2018/hash/a19744e268754fb0148b017647355b7b-Abstract.html
非常に良い解説記事が以下のリンクであるので、ここでは補足を基本的にする

Introduction
Noise Transition Matrixはインスタンス依存などもあっても、性能に限界がある。今はCleanなラベルをできるだけ選び出して、それらを使って訓練するSample Selectionである。
Mentor Net 📄![]() 2018-ICML-MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels の先行研究では、小さいCleanな集合でまずMentor Netを訓練し、それをもとにどのサンプルにどれほどの重みをつけるべきかがMentor Netの出力になるので、それからStudent Netを訓練する。(まずは単独でMentor Netを訓練。そして、Mentor Netからの情報でStudent Netを訓練→Student Netの情報からMentor Netを訓練し、この2つを繰り返す)ここでCleanなデータセットがないと、既存のカリキュラム学習をするしかない。
2018-ICML-MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels の先行研究では、小さいCleanな集合でまずMentor Netを訓練し、それをもとにどのサンプルにどれほどの重みをつけるべきかがMentor Netの出力になるので、それからStudent Netを訓練する。(まずは単独でMentor Netを訓練。そして、Mentor Netからの情報でStudent Netを訓練→Student Netの情報からMentor Netを訓練し、この2つを繰り返す)ここでCleanなデータセットがないと、既存のカリキュラム学習をするしかない。
ほかにも、Decouplingは2つのNetworkを同時に訓練するが、同じサンプルに対して、違う判断結果となるものだけを更新していく。気持ちとしては、訓練の早期での更新はラベルが間違っているからであるが、十分に学んだあとはNoisy Labelによって望ましくない更新が起きているから。だったら、2つのネットを訓練し、その判断(ラベルとそれぞれの予測器の合致度)が同じ=両方の学習器がそのサンプルについて同じ認識(ラベルからの遠近を問わず)なら、そのサンプルについての学習はもうしない。なぜならサンプルのラベルがNoisyラベルでありうるし、2つのネットの見解が一致したのにさらに学習してNoisyにフィットされても困るから。
Method

- Cleanなデータ=特徴量がわかりやすい。Noisyなデータ=特徴量がわかりづらいという仮定。
- Memorization EffectによってDNNはCleanなデータ=わかりやすいデータを先に学習し、Noisyのものは後で学習する。
- ならば、(特に訓練の途中からは)損失が少ない=ほぼ正解であるデータでさらに学習を進めるのはOK。大きな損失を持つデータはラベルが間違っているからである可能性があるので、あえて学習をしない!
- 最初は多くのデータで学習をするが、次第に損失の少ないデータに絞って学習をする。
- 📄
 2019-PMLR-[SELFIE] Refurbishing Unclean Samples for Robust Deep Learning と矛盾する感じがするが、無向はラベルを修正することを前提に全数を学習させに行く。
2019-PMLR-[SELFIE] Refurbishing Unclean Samples for Robust Deep Learning と矛盾する感じがするが、無向はラベルを修正することを前提に全数を学習させに行く。
- 📄
- 2つ同時に訓練することによって、2つの識別境界を作る。それぞれがラベルノイズをフィルタリングして、正しいと思われるサンプルの損失だけで、相手のネットのパラメタを更新させる。
- 別の視点を持つネットに、自分では気づけないようなノイズでも、相手のネットが持つ識別能力でできるように。
Co-trainingとの関係
同時にネットを訓練すると、1つだけ訓練するよりもいい結果が出るCo-Trainingからこの論文は着想を得た。しかし、直接的に完全に互換できるわけではない。
Co-Trainingとは、以下のようなものである。
- 少量のラベル付きデータと、大量のラベルなしデータを用意する。
- 基本人間が見るべき特徴量を決めて、識別器Aは特徴Xに着目、BはYに着目というように、それぞれの視点でラベルありデータで学習してもらう。
- 識別器Aがラベルなしデータについて予測し、自信のあるデータにそのラベルを付けて、Bの追加の訓練データにする。Bも同様にAの追加データを生成する。
- 上のものを繰り返す。
これとTo-teachingの違いは以下のようになる。
- Co-Trainingはそれぞれが2つの特徴量の集合=視点を持つが、Co-teachingは同じようにbackwardさせるので、視点は1つだけ(学習の初期値が違うので収束までの道筋が違うだけ)
- Co-TrainingはMemorization Effectを使っていない。
- Co-TrainingはSelf-supervised Learning。こっちはNoisy Labels。
Result
MNIST, CIFAR-10, CIFAR-100を使った。ノイズはいつも通りの対称ノイズと非対称ノイズ。説明はこの記事がわかりやすい。
📄![]() 2020-Survey-A Survey of Label-noise Representation Learning: Past, Present and Future
2020-Survey-A Survey of Label-noise Representation Learning: Past, Present and Future
比較手法
比較する手法は以下の通り(参考記事より引用) 一部修正あり
- Bootstrap: 正解ラベルと予測ラベルを重み付きで合成したものを、正解ラベルとして取り扱う手法。それで学習をする。
- S-model: noise transition matrix(どのクラスとどのクラスの間でどれだけラベルの誤りが起こりやすいかを表す行列)を推定する手法
- F-correction: 推定したnoise transition matrixで予測を補正する手法
- Decoupling: 2つのDNNが異なる予測をしたデータを学習する手法
- MentorNet: 事前学習した教師モデルでnoisy labelsをふるい分け、生徒モデルをnoisy labelsにロバストに学習する方法
- Co-teaching:提案手法
ネットワーク構造など
backbornは、9層のCNNであり、Temporal Ensembling, Virtual Adversarial Trainingに従っているらしい。最適化手法はAdamである。
MNISTの結果
Zennにあるのでそれを見よう。
CIFAR-10, CIFAR-100の結果
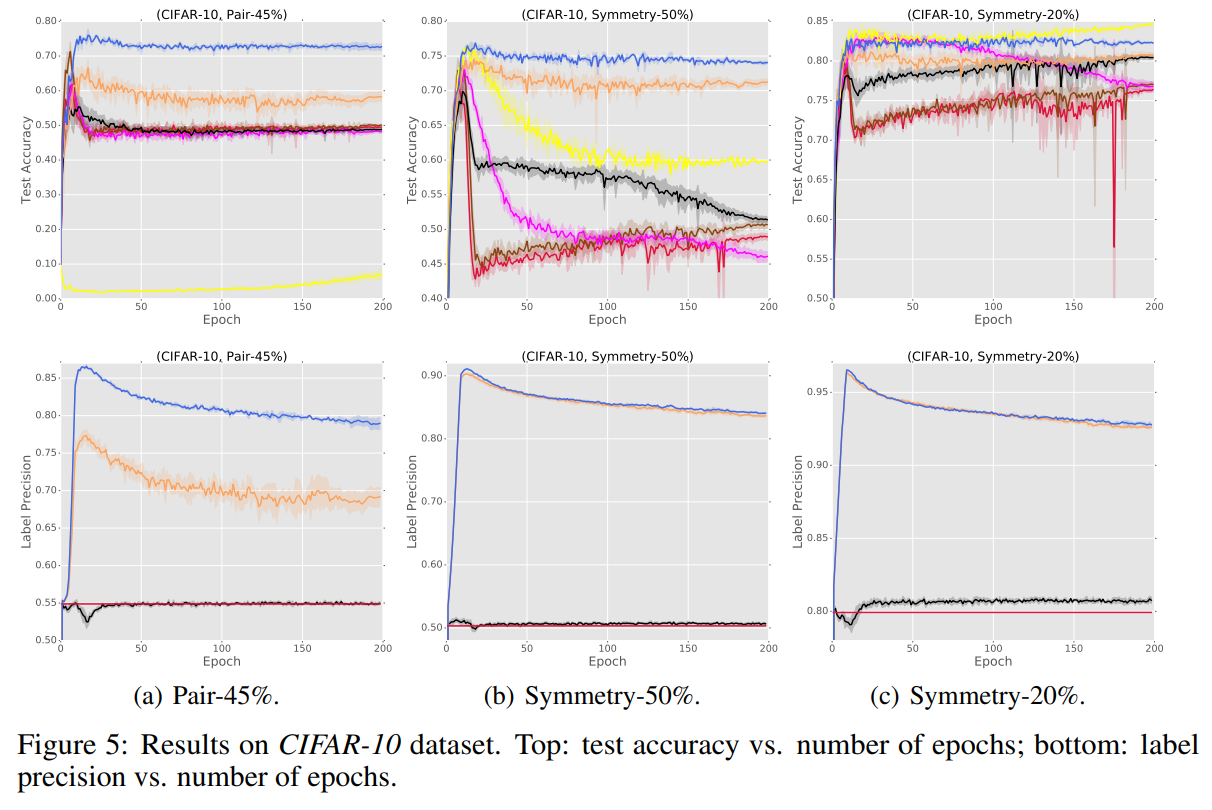
CIFAR-10の結果。提案手法は青。上はTestのAccuracy。下はLabel予測の正解度合。
学習が進むと基本的に過学習傾向になって、特にラベル予測の正解度合いが壊れていく。抜群にいいのはMentorNetと提案手法であるが、その中でもMentor Netを提案手法が基本的に上回っているんだからすごいですよ。
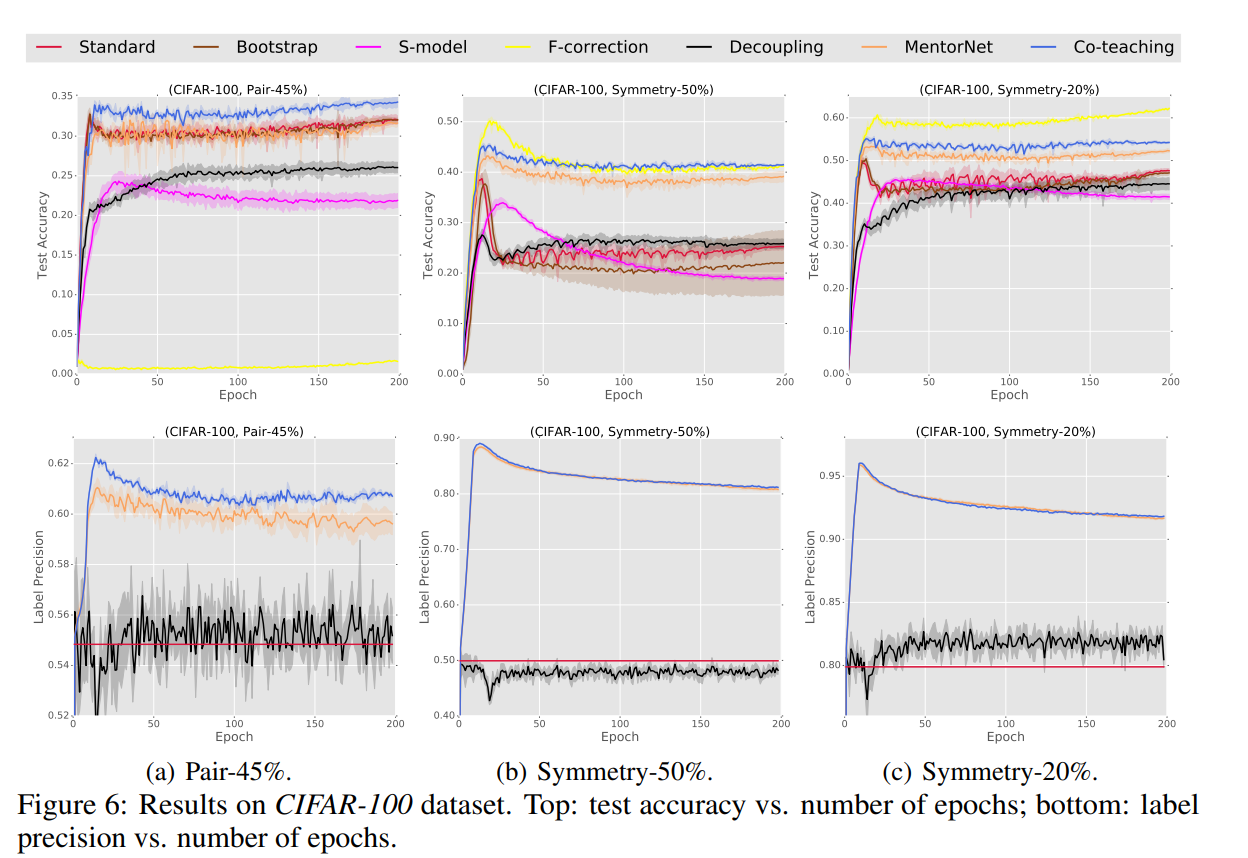
CIFAR-100の結果。提案手法は青。上はTestのAccuracy。下はLabel予測の正解度合。
CIFAR-10と同様な傾向が見て取れる。
まとめ
この手法は特に高ノイズ率の場合で活躍する。低ノイズ率は普通に既存のノイズ変換行列のF-Correctionのほうがよさそう。